Recently I’ve been trying to get postings of house rentals in Thimphu. The initial idea was to build a web-scraper and sift through the html to find the information. I did end up building a web scraper but used it in a different manner.
It’s become a habit now to consult with ChatGPT before I do anything. As I was bouncing off ideas and getting suggestions, ChatGPT recommended using Facebook Graph API.
So I went in a rabbit hole learning about GraphAPI and how I could use it. GraphAPI is pretty cool, you can basically get most data from Facebook if you are approved plus have the necessary permissions. It did allow me to get the postings of groups I am an admin of but since I’m not the admin of “Rent a house in Thimphu”, this approach was a bust. If I wanted the groups data, I needed to build a Facebook App and get one of the admins to install the app on the group which I am definitely not gonna do.
And the next counsel of advisors I hit up was reddit. There wasn’t much information except for a single person who posted about doing the exact same thing (getting posts from public groups). She executed in the way I initially thought: get some css classes and html tags and look for those. At this point scraping through the random css names and html divs didn’t sound like the most reliable way to do it. And another approach to intercept the API responses was brewing in my head and when I saw one of the users comment that that might be a better approach I decided to sift through Facebooks Network calls.
When I first looked at the API responses I was paralyzed. The responses looked gibberish and I thought it might be like google’s network responses which are so hard to decipher. For context the network calls and responses look something like this:
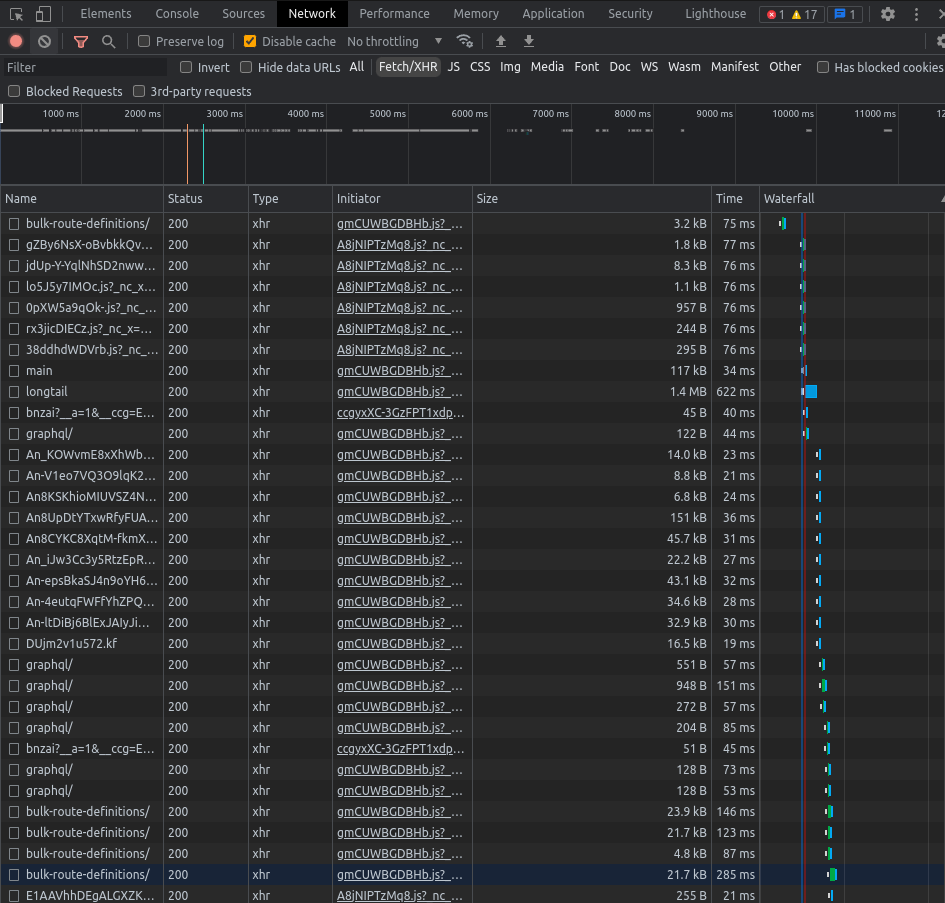
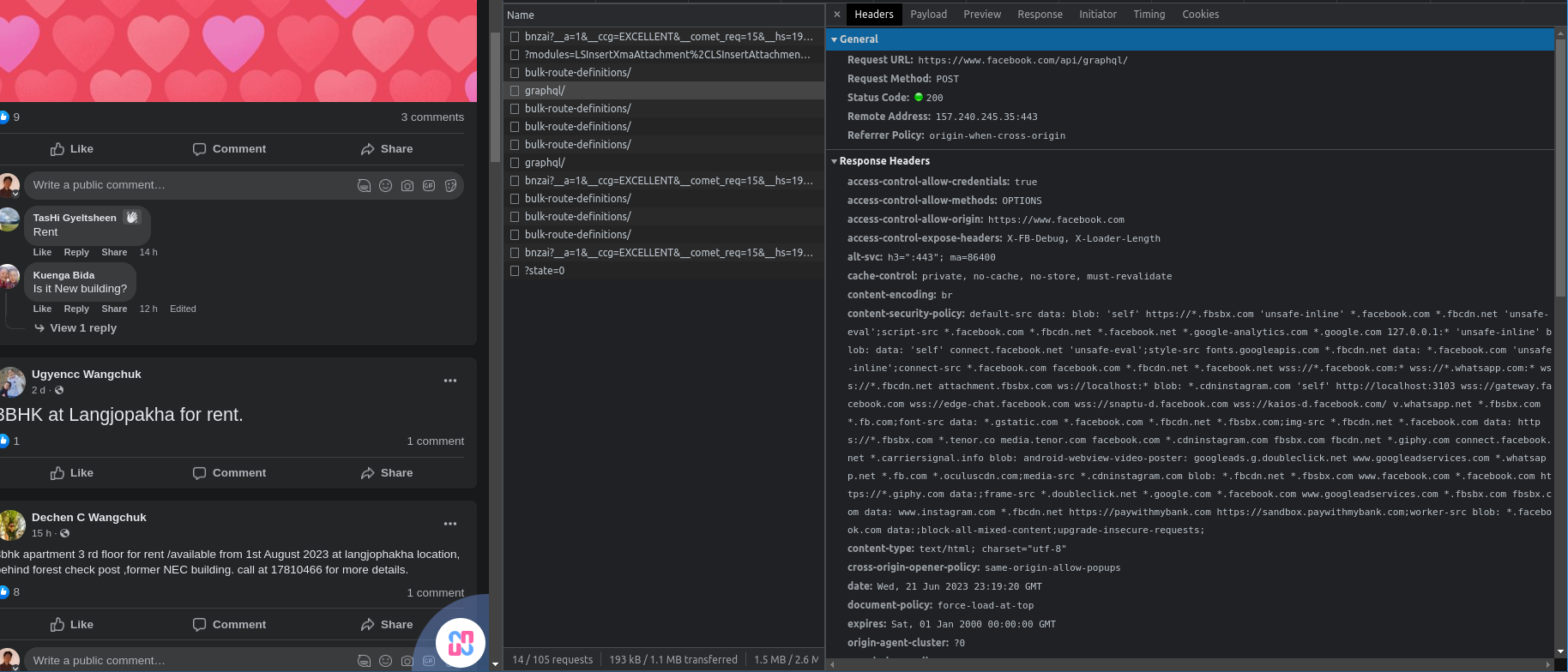

After sulking that I was not a good developer and that I’d never make it in life for a few days, I finally grew a pair and put the response in JSON formatter. Some pretty formatting did the job and upon analyzing it further: the response is actually quite interesting.
Facebook seems to be using some form of ssr since even the css classes and html attributes are sent in the response. The response type is also text/html. The response is also very huge although each API call only returns three posts.
With this the hard part was over and coding this wasn’t that bad.
I first hooked up Seleniumwire: seleniumwire is a mod on selenium and it allows you to intercept requests and response.
Once you have a function to intercept requests, intercepting is as easy as this:
browser_driver.response_interceptor = your_response_interceptor_function
This is what my response interceptor function looks like
def feed_response_interceptor(request, response):
if response.headers.get('content-type') == 'text/html; charset="utf-8"':
try:
data = (decode(response.body, response.headers.get('Content-Encoding', 'identity')))
data = data.decode('utf-8')
for line in data.splitlines():
data_expression = r'"data":{"node":.*}'
match = re.search(data_expression, line)
if match:
json_data = json.loads(line)
post_id = get_post_id(json_data)
post_message = get_post_message(json_data)
attachment_uris = get_attachments(json_data)
df.add_to_data(post_id, post_message, attachment_uris)
except:
print("Error parsing data")
The response interceptor does not discriminate and I didn’t look at the docs enough to know a way to set it up so I just did a custom function like above with the help of ChatGPT. Other than some false positives I have not had any issues with the filtration
I was mainly interested in the post message. Most postings are in the form of free form text which are usually along the lines of: “House for rent available in Kabesa, 3bhk”.
Here is how I got the post message
def get_post_message(data):
initial_path = 'data.node.group_feed.edges[0].node.comet_sections.content.story.message.text'
secondary_path = 'data.node.comet_sections.content.story.message.text'
if pydash.get(data, initial_path):
return pydash.get(data, initial_path)
elif pydash.get(data, secondary_path):
return pydash.get(data, secondary_path)
else:
return ""
I have the initial path and secondary path because the response looks something like this:
{data: {node: group_feed: {....}}}
{data:{node: {come_sections: {...}}}}
{data:{node: {come_sections: {...}}}}
As I said before the posts came in threes but the first post had a different body than the latter two. It was almost similar but the first one has a bit more information.
As I was scraping through the data, I found that the response also gave attachments associated with the post. And attachments in this case is mostly images of the house or apartment. As can be seen below the process to get the attachments was similar to the text extraction.
def get_attachments(data):
initial_attachments_path = 'data.node.group_feed.edges[0].node.comet_sections.content.story.attachments[0]'
secondary_atachments_path = 'data.node.comet_sections.content.story.attachments[0]'
if pydash.get(data, initial_attachments_path):
return get_subattachments_uri(pydash.get(data, initial_attachments_path))
elif pydash.get(data, secondary_atachments_path):
return get_subattachments_uri(pydash.get(data, secondary_atachments_path))
return []
I got both the attachments and post message from the response of the same API. Currently working on the hard part of extracting useful information from it(not that hard with ChatGPT), planning to use ChatGPT functions to do that.